V první části použijeme volně dostupný software pro čtení textu z obrázků. Pro tuto úlohu vytvoříme takzvanou pipeline-u tvořenou dvěma komponentami. První je lokalizace textu v obrázku, kde využijeme python modul keras-ocr. Druhá komponenta je pak samotný systém pro přepis obrázku do textu (teda OCR systém) s názvem Tesseract.
V druhé části tutorialu si ukážeme, jak můžeme OCR nasadit na server a pomocí API volání vytěžovat text z obrázků. Na hostování této mikro služby využijeme Amazon web services (AWS).
Co to je OCR?
Optické rozpoznávání znaků (OCR – optical character recognition) je proces, převádějící text ve fotce-obrázku do strojově čitelného textového formátu. Pokud například naskenujete formulář nebo účtenku, počítač naskenovaný obrázek uloží jako fotku, resp. obrázek. To znamená, že nelze použít textový editor k jejich úpravě, vyhledávání nebo počítání slov či znaků. Můžeme však použít OCR k převodu obrazu textu na editovatelná textová data. S těmi pak už pracovat lze.
Proč je OCR důležité pro Váš business?
Většina pracovních procesů (nejenom v backoffice) zahrnuje přijímání informací z tištěných médií. Papírové formuláře, faktury, naskenované právní dokumenty a tištěné smlouvy. Zpravidla stohy papírů a kilometry šanonů. Ukládání a správa takových objemů tištěných dokumentů zaberou nejenom spoustu fyzického prostoru ale i času k jejich organizaci i vlastnímu užití. Správa dokumentů digitálně tedy zní jako správná cesta, skenování dokumentů do podoby obrázků však může představovat problémy. Tento proces vyžaduje ruční zásah a může být zdlouhavý a pomalý. Navíc digitalizací takových dokumentů vznikají obrazové soubory s textem, který je v nich skrytý a nečitelný. Text v obrázcích nemůže být zpracován jen běžnými programovacími metodami. Technologie OCR řeší problém převodem textových obrázků na textová data, která lze analyzovat jiným softwarem. Data pak lze použít k provádění analýz, zefektivnění operací, automatizaci procesů a zvýšení produktivity.
Tesseract
Tesseract je OCR software licencovaný pod Apache License, umožňující využití i pro naše účely. V současnosti je jednodušší využít již připravený OCR systém, než vytvářet vlastní – díky jejich popularitě existuje dlouhá řada dostupných alternativ. Tesseract byl původně vyvinut firmou HP v roce 1980, v roce 2005 se stal open-source softwarem a od roku 2006 je udržován a spravován Googlem. Poskytuje podporu pro Windows, Linux i MacOS.
Tesseract pro Windows můžeme stáhnou zde: https://github.com/UB-Mannheim/tesseract/wiki
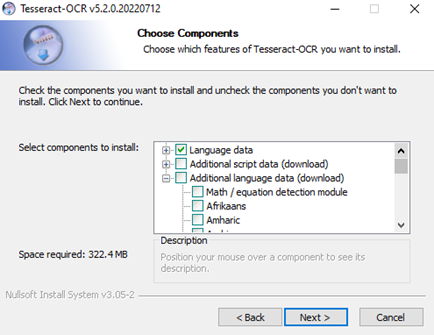
Postup instalace bude trochu jiný pro užívatele, kteří využívaj Linuxové distribuce. Po vlastní instalaci by to mělo být téměř identické. Samotná instalace by měla být celkem přímočará, jediné na co je dobré si dát pozor je potřeba doinstalovat podporu českého jazyka (případně jiných jazyků). Uděláme to v kroku instalace „Choose Components“ (viz. Obrázek níže), kde rozklikneme „Additional language data“ a najdeme český jazyk, případně pokud chcete používat jiný než latinský script vyberte jej v tomto kroku. Pak už stačí jenom dokončit instalaci.
Keras OCR
Keras-ocr poskytuje předpřipravené modely pro OCR a komplexní trénovací metody pro vytváření nových modelů.
keras-ocr — keras_ocr documentation
Environment dependencies
Python verzie 3.9.7

Tyto závislosti je možné uložit do textového souboru s názvem „requirements.txt“, následně instalovat příkazem pip install -r requirements.txt
GitHub – madmaze/pytesseract: A Python wrapper for Google Tesseract
Direct technologies repository – zde naleznete všechny zdroje a kódy použité v tomto článku
Pojďme na to!
Pro práci využiju prostředí VS Code s rozšířením pro jupyterNotebook, protože v tomto případě umožní rychlé a komfortní zobrazení fotografií. Obrázky můžete využít libovolné.
Jako první si musíme naimportovat moduly, které budeme využívat:
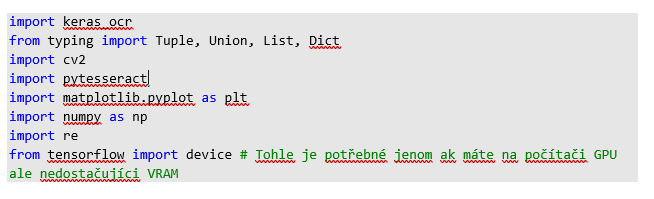
Pokud se povedlo, povíme modulu pytesseract kde má hledat tesseract.exe (pokud používáme Windows). V prvním řádku doplníme cestu kde jsme nainstalovali Tesseract. V tomto kroku si můžeme vypsat i dostupné jazyky.

Pojďme se podívat, zda je všechno nastaveno správně. A to tak, že si načteme libovolnou fotografii (ideálně obsahující text 😊) a zkusíme z ní přepsat text. Obrázky budeme konvertovat do černobílé barevné škály, ulehčuje to čtení textu. Nejprve si jen obrázek zobrazíme pomocí matplotlib-u, následně přepíšeme text.


Můj testovací obrázek se na první pohled zdá jako jednoduše čitelný – velký a jasný text, žádné pozadí, dobrý barevný kontrast. A co na to Tesseract? Je evidentní, že se jedná o anglický text, budu hodný a napovím Tesseractu a pomůžu mu nastavením jazyka na angličtinu.
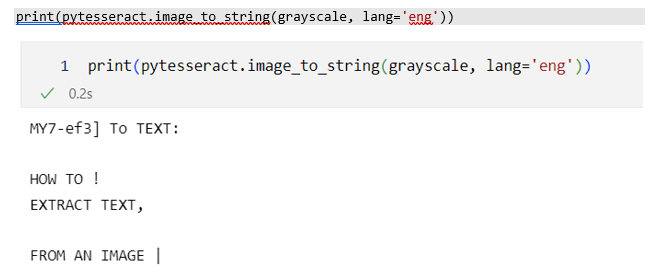
Tento příkaz už nám vrací konkrétní text, ale kvalita nabízeného přepisu je poměrně slabá, proč? Tesseract je známý tím, že k uspokojivé funkčnosti, musí mít obrázky dobře předzpracované. Na našem příkladě vidíme, že jednotlivá slova/hesla mají různou velikost. K specifickému zpracování se věnuje například Improving the quality of the output | tessdoc (tesseract-ocr.github.io). V našem setup-u však zkusíme použít keras a jejich OCR balíček (teda keras-ocr). To nám umožní „vystřihnout“ text z fotek, a tyto výstřižky pak nechat přepsat Tesseractem. Tím snížíme šum a variabilitu, a potencionálně zvýšíme kvalitu přepisu.
V Directu jsme si tento model (dále už jenom detector) přetrénovali tak, aby zachytával i diakritiku specifickou v českém jazyce (k tomu jsme využili cloudové služby AWS). Základní model byl natrénován na anglických textech a z toho důvodu často ořezává českou diakritiku háčky, čárky, kroužky nebo přehlásky (jinými slovy nevidí znaky nad písmenem). V tomto tutoriálu si ale ukážeme práci se základním modelem, který funguje dostatečně dobře. Při prvním spouštění tohoto příkazu, se předtrénované koeficienty modelu stáhnou na váš lokální počítač, může to zabrat nějakou minutku. Koeficienty mají přibližně 81 MB.
![]()
Abychom mohli detector použít budeme muset fotku předzpracovat, a to pomocí definované funkce:
Teď už si můžeme vygenerovat takzvané bounding boxes – to je název pro ohraničení textu v obrázku. Osobně na predikci použiju CPU,(moje grafická karta totiž nemá dostačující VRAM). Vysvětlení jednotlivých parametrů můžete najít např. zde: API — keras_ocr documentation (keras-ocr.readthedocs.io).
Po detekci bounding boxes musíme tato ohraniční ješte upravit, aby se shodovala s originálním obrázkem.


Pojďme si pro ukázku vykreslit navržené bounding boxes, které náš model našel, abychom se ujistili, zda pracuje správně:
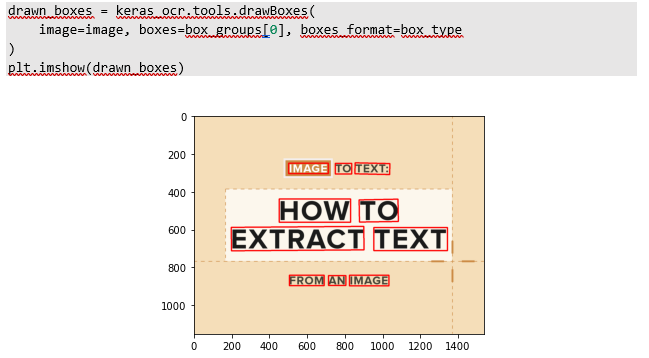
Výborně! Je zřetelné, že model našel texty na obrázku a jejich ohraničení „není příliš volné“. Teď musíme vyřezat texty z obrázku. Na takovou úlohu si vydefinujeme funkci, která určí středy X a Y souřadnic. Z obrázku níže vidíte, že z detekcí máme čtyři páry souřadnic (x, y), pokud pracujeme s numpy polem potřebujeme jenom dva páry (x1_mid, y1_mid) a (x2_mid, y2_mid).




To by mohlo stačit! Pojďme si nyní vyzkoušet přepis na dvou obrázcich. Jeden bude vzorový řidičský průkaz a druhý vzorový občanský průkaz. Při volání funkce predict() můžeme dostat upozornění od tensorflow na takzvaný retracing. Je to kvůli definici predikce v balíčku keras_ocr ( detector.detect() )

V tomto kroku je potřeba vygenerovaný výstup zpracovat podle požadavků. V případě identifikačních dokumentů dáva smysl vytvořit json strukturu kde klíčem je název pole, například „Příjmení“ a hodnota je „RŮŽIČKOVÁ“, anebo v jiných případech „číslo faktury“ a „123456“.
Pokud se podíváme na detekce, vrácený text z pravého horního boxu “Z” z řidičského průkazu nevypadá správně, pojďme se podívat detailněji. Vykreslíme jsi předikované bounding boxes a hned je jasné odkud pochází.

Zvládli jste to na jedničku.
Právě jste dali dohromady Váš vlastní OCR systém. Určitě na něm budete chtít doladit ještě spoustu dalších věcí a drobností, ale základní stavební prvky jsou hotové.
V dalším díle tutorialu se podíváme, jak nasadit naše OCR na server (konkrétněji na EC2 instanci v prostředí AWS) a pomocí API vytěžovat texty z vlastních dokumentů všeho druhu.
Tento příspěvek pro Vás připravil Marek, datascientist Direct technologies